The Truth About Hash Tables
Let's Ask Google
Data structures were among the first things we learned at Hack Reactor. I knew what an array and object were, but not much else. Some of my classmates already knew binary search trees and graphs.
Arguably, the first difficult data structure you encounter in the curriculum is the Hash Table. A Google of "hash table" gives you this:
In computing, a hash table (hash map) is a data structure used to implement an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the correct value can be found.
That doesn't help me one bit.
See what I did there?
"Bit"? Bazinga!
A Beginner's Definition
A hash table is an object.
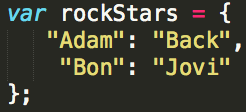
However, instead of just inserting a key-value pair, you're going to run the key through a hashing algorithm. A hashing algorithm takes an input, obliterates it, and returns a "hash".

In this example, our hashFunction() takes two parameters, 1) the key and 2) the maximum size of the hash table. You decide the maximum size. It will return a number (the hash) between one and two. We will use this hash in place of the key "Adam"; insert function will make use of this hash function.

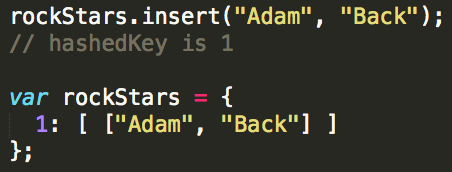
Why, for all things, why?
This is my common complaint in computer programming. The answer is generally, "Because it's a really good idea."
Hash tables are generally used to store sensitive data. The cool thing about hash functions is that they're one-way machines.

There is a common misconception that hashing is the same as encryption. It is not. Encrypted data can be decrypted back to its original state. A hashed value cannot.
Hash tables are also pretty quick, with constant-time lookup as the goal.
Collisions
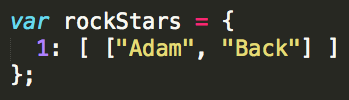
In the hash table above, the key-value pair was stored as a nested array, but I never said why. It's to handle collisions.
This is a very small hash table; its maximum size is only two. It's bound to run out of room! What to do? Let's add some more items to the hash table first to find out.

So now the hash table looks like this:
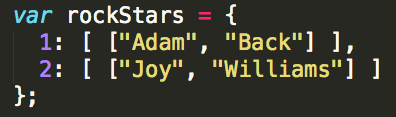
The next insertion. Oh the next insertion.

I hid a complication in the insert function earlier. I ignored that a collision could ever happen. Let's fix that with pseudocode:
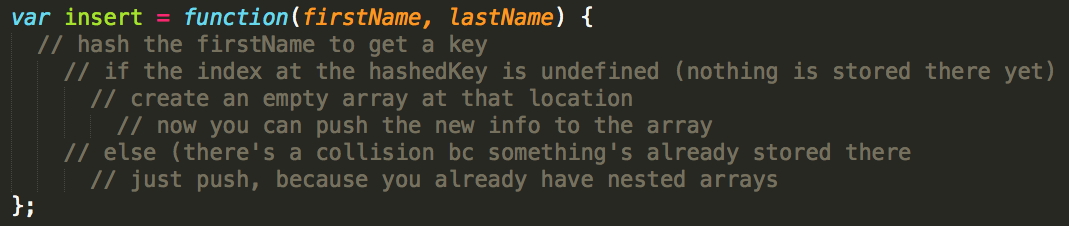
In code:
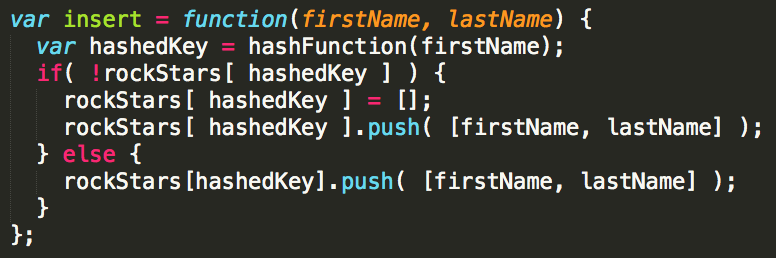
So, now your hash table looks like this:

What the internet won't tell you:
(until now)What do you do if you want to insert a key-value pair that has the same key:

Adam will get hashed and be inserted into the 1 location.

However, when you retrieve in a hash function, you only specify the key:

Which Adam will get returned? Which Adam are you even looking for?
The truth!
When you insert the same key, it should update the value. It doesn't replace the whole array or store a second Adam.
Let's update our code:
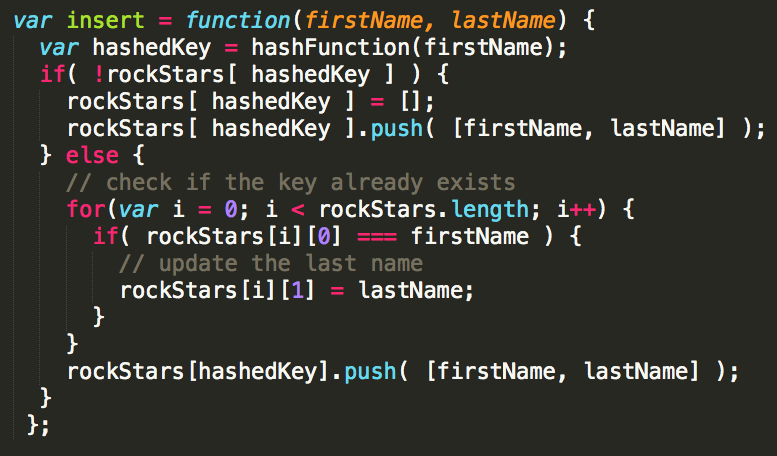
Now, when we add Adam Sandler, Adam Back will update to have a different last name.

Voila.
DISCLAIMER: While I've tried to cover a lot about hash tables, I still simplified some things. For example, when hash tables fill up, they can expand so less collisions occur.
comments powered by Disqus